Los datos como activo: DataFi abre nuevas oportunidades en el sector
«Vivimos en una época en la que el mundo compite por desarrollar los modelos de IA más avanzados. Si bien la capacidad financiera y la arquitectura son importantes, la verdadera ventaja sostenible reside en los datos de entrenamiento».
—Sandeep Chinchali, Chief AI Officer, Story
El potencial del sector de datos para la IA: una visión desde Scale AI
Este mes, uno de los grandes titulares del mundo de la IA es la demostración de capacidad financiera de Meta, con Mark Zuckerberg volcado en captar talento para formar un equipo de IA de referencia mundial, con participación destacada de investigadores chinos. Lidera Alexander Wang, fundador de Scale AI, que con solo 28 años ha creado la empresa desde cero—ahora valorada en 29.000 millones de dólares—, y da servicio tanto al ejército de EE. UU. como a competidores como OpenAI, Anthropic y la propia Meta. Todos estos gigantes de la IA confían en Scale AI para sus servicios de datos, cuya actividad principal es proporcionar enormes volúmenes de datos etiquetados y de máxima calidad.
¿Por qué Scale AI destaca como unicornio?
La clave está en su temprana comprensión del papel central de los datos en la industria de la IA.
La computación, los modelos y los datos forman los tres pilares del ecosistema IA. Podemos imaginar el modelo como el cuerpo, la computación como el alimento y los datos como el conocimiento y la experiencia acumulados.
Desde la aparición de los grandes modelos de lenguaje, la prioridad del sector ha pasado de la arquitectura de modelos a la capacidad computacional. Casi todos los modelos punteros han adoptado los transformers como arquitectura estándar, con innovaciones periódicas como MoE o MoRe. Los grandes actores construyen sus propios superclusters o firman acuerdos a largo plazo con proveedores de nube hiperescala como AWS. Cuando la infraestructura computacional está garantizada, el foco se traslada al aumento del valor estratégico de los datos.
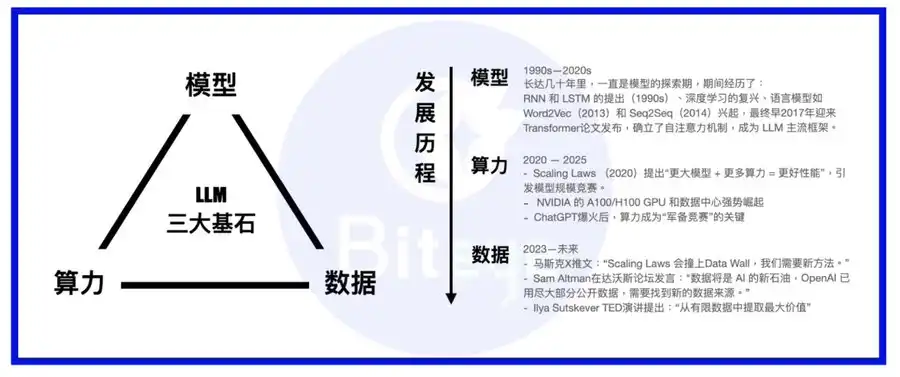
A diferencia de empresas consolidadas de datos como Palantir, Scale AI está dedicada a crear una base de datos robusta para la IA. Su propuesta va mucho más allá de explotar conjuntos de datos ya existentes: se orienta a la generación de datos a largo plazo, organizando equipos de entrenadores de IA formados por expertos para generar datos de máxima calidad para el entrenamiento de modelos.
¿No te convence este modelo de negocio? Veamos cómo se entrenan los modelos.
Entrenar un modelo de IA implica dos fases: preentrenamiento y ajuste fino.
El preentrenamiento es comparable al proceso de aprendizaje de un niño: la IA absorbe enormes cantidades de texto y código de internet para aprender lenguaje natural y comunicación básica.
El ajuste fino sería como la educación formal, donde existen respuestas correctas e incorrectas. Igual que las escuelas modelan a los alumnos según su currículo, usamos conjuntos de datos adaptados y preparados para entrenar modelos en habilidades específicas.

Probablemente ya habrás percibido que necesitamos ambos tipos de datos:
· Por un lado, datos que requieren poco procesamiento, donde lo prioritario es la cantidad. Suele tratarse de datos recopilados de plataformas de contenido generado por usuarios (Reddit, Twitter), repositorios de acceso abierto o bases de datos privadas corporativas.
· Por otro lado, están los datos equivalentes a manuales técnicos: diseñados y seleccionados con esmero para transmitir habilidades o competencias concretas, que exigen depuración, filtrado, etiquetado y feedback humano.
Ambos tipos constituyen el núcleo del mercado de datos para IA. Aunque tecnológicamente los datasets puedan resultar simples, el consenso es que, cuando la escalabilidad computacional alcanza su techo, serán los datos el gran factor diferenciador para los proveedores de modelos avanzados.
A medida que evolucionan los modelos, los datos de entrenamiento cada vez más precisos y especializados resultan determinantes para su rendimiento. Por seguir con la analogía: si entrenar un modelo es como formar a un maestro de artes marciales, los datos serían el manual definitivo de entrenamiento, la computación el elixir mágico y el modelo la predisposición natural.
Desde un enfoque vertical, el sector de datos para IA es una apuesta de crecimiento exponencial a largo plazo. A medida que se acumula el trabajo inicial, estos activos de datos generan rendimientos compuestos y se revalorizan con el tiempo.
Web3 DataFi: el ecosistema óptimo para la generación de datos de IA
Frente a la enorme plantilla de anotadores remotos que emplea Scale AI en países como Filipinas y Venezuela, Web3 aporta ventajas singulares en el ámbito de los datos para IA a través del concepto DataFi.
Entre los principales beneficios de Web3 DataFi se encuentran:
1. Propiedad, seguridad y privacidad de los datos gracias a contratos inteligentes
Con el agotamiento de las fuentes públicas de datos, lograr acceso a datos inéditos o incluso privados se ha vuelto crucial. Surge así el dilema: ¿vender irrevocablemente tus datos a un agregador centralizado o mantener tu propiedad intelectual en blockchain, conservando la titularidad y usando contratos inteligentes para dejar constancia transparente de quién, cuándo y con qué fin accede a tus datos?
En el caso de datos sensibles, tecnologías como las pruebas de conocimiento cero (zero-knowledge proofs) y hardware Trusted Execution Environment (TEE) garantizan que solo las máquinas accedan a la información, preservando la privacidad y evitando filtraciones.
2. Arbitraje geográfico nativo: la descentralización atrae al mejor talento internacional
Es momento de replantear los modelos laborales tradicionales. En vez de una búsqueda global y centralizada de mano de obra barata, como realiza Scale AI, la arquitectura descentralizada de Web3 y sus incentivos transparentes vía contratos inteligentes permiten que una fuerza laboral diversa y global aporte datos y reciba una remuneración justa.
En tareas como el etiquetado o la validación de modelos, el enfoque descentralizado fomenta la diversidad y reduce el sesgo, clave para lograr datos de alta calidad.
3. Incentivos y pagos totalmente transparentes gracias a blockchain
¿Quieres minimizar los fallos operativos? Los contratos inteligentes en blockchain permiten desplegar incentivos públicos y automáticos, superando los sistemas manuales y opacos tradicionales.
Con la ralentización de la globalización, aprovechar el arbitraje geográfico mediante sucursales se vuelve cada vez más difícil. La liquidación on-chain permite sortear estos obstáculos y facilita la participación y el pago internacional sin trabas.
4. Mercados de datos eficientes, abiertos y sin intermediarios
Los intermediarios que cobran comisión constituyen una barrera constante. En vez de depender de empresas de datos centralizadas, las plataformas on-chain pueden funcionar como mercados abiertos, transparentes y directos, similares a Taobao, conectando a compradores y vendedores sin fricción.
La demanda de datos de IA en blockchain será cada vez más segmentada y sofisticada, y solo los mercados descentralizados podrán escalar para cubrir y monetizar eficazmente esa necesidad.
DataFi: la opción de IA descentralizada más accesible para el usuario minorista
Aunque las herramientas de IA han facilitado la entrada y la IA descentralizada aspira a romper los monopolios, la realidad es que muchos proyectos permanecen fuera del alcance de los usuarios no técnicos. Formar parte de redes de computación descentralizadas suele requerir hardware caro y los mercados de modelos pueden resultar complejos.
En cambio, Web3 ofrece oportunidades inéditas y realmente accesibles para el usuario medio en la revolución de la IA. No hacen falta contratos laborales abusivos: basta con conectar una wallet y participar. Puedes aportar datos, etiquetar respuestas de modelos usando tu criterio, evaluar modelos, o emplear herramientas de IA sencillas en tareas creativas y transacciones de datos, normalmente sin ninguna barrera técnica, especialmente para quienes ya están familiarizados con los airdrops.
Proyectos DataFi líderes en Web3 a seguir de cerca
El dinero marca la tendencia. La inversión de 14.300 millones de dólares de Meta en Scale AI y la subida por cinco en bolsa de Palantir confirman el potencial de DataFi en Web2; en Web3, DataFi también lidera la captación de fondos. Destacan los siguientes proyectos:
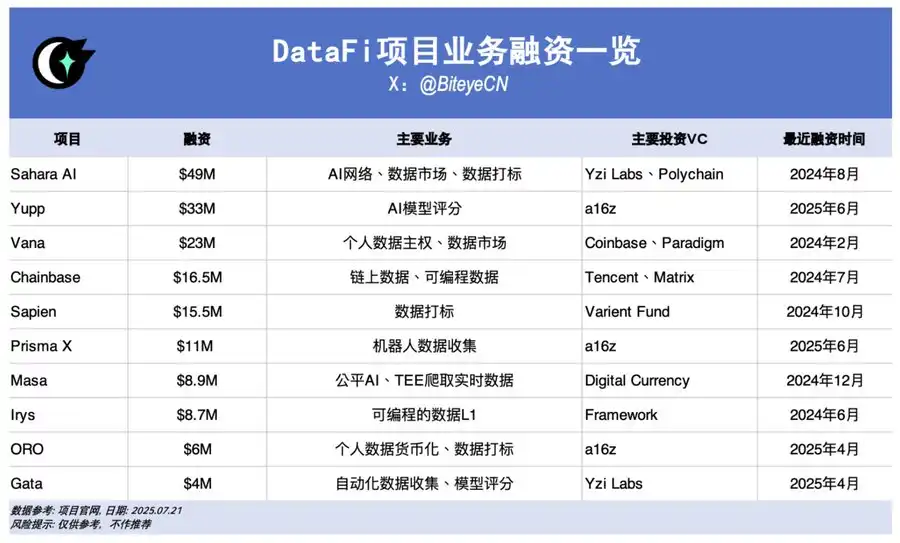
Sahara AI, @SaharaLabsAI, recaudó 49 millones de dólares
Sahara AI propone una superinfraestructura de IA descentralizada y un mercado de datos. Su Data Services Platform (DSP) en beta estará disponible a partir del 22 de julio y recompensará a los usuarios que aporten y etiqueten datos.
Enlace: app.saharaai.com
Yupp, @yupp_ai, recaudó 33 millones de dólares
Yupp es una plataforma de retroalimentación para IA donde los usuarios evalúan las respuestas de modelos, comparan diferentes salidas ante la misma instrucción y votan cuál es mejor. Los Yupp points obtenidos pueden canjearse por stablecoins como USDC.
Enlace: https://yupp.ai/
Vana, @vana, recaudó 23 millones de dólares
Vana permite a los usuarios convertir datos personales—como historial de navegación o actividad social—en activos digitales. Los datos se agrupan en DataDAOs y pools de liquidez para IA, recompensando en tokens a quienes contribuyen.
Enlace: https://www.vana.org/collectives
Chainbase, @ChainbaseHQ, recaudó 16,5 millones de dólares
Chainbase se centra en datos en blockchain, estructurando la actividad de más de 200 cadenas en activos monetizables para desarrolladores de DApps. Los datos se indexan y procesan con su sistema Manuscript y Theia AI. Actualmente, la participación minorista es reducida.
Sapien, @JoinSapien, recaudó 15,5 millones de dólares
Sapien transforma el conocimiento humano a escala en datos de entrenamiento para IA de primer nivel. Cualquier usuario puede etiquetar datos en su plataforma, con control de calidad mediante revisión por pares. Se fomenta la reputación a largo plazo y el staking para maximizar las recompensas.
Enlace: https://earn.sapien.io/#hiw
Prisma X, @PrismaXai, recaudó 11 millones de dólares
Prisma X aspira a ser la capa de coordinación abierta para robots, poniendo la recopilación de datos físicos en el centro. Aún en fases iniciales, permite a los usuarios participar apoyando la recogida de datos, operando robots a distancia o completando actividades tipo quiz para sumar puntos.
Enlace: https://app.prismax.ai/whitepaper
Masa, @getmasafi, recaudó 8,9 millones de dólares
Masa lidera el ecosistema Bittensor con sus subredes de datos y agentes. La subred de datos ofrece acceso en tiempo real mediante hardware Trusted Execution Environment (TEE) para recopilar datos de X/Twitter. Actualmente, participar como minorista es caro y complejo.
Irys, @irys_xyz, recaudó 8,7 millones de dólares
Irys se centra en almacenamiento y computación programable, eficientes y económicos, para IA y DApps intensivas en datos. Aunque las oportunidades para que los usuarios aporten datos son acotadas, la testnet activa permite múltiples formas de participación.
Enlace: https://bitomokx.irys.xyz/
ORO, @getoro_xyz, recaudó 6 millones de dólares
ORO permite a cualquiera contribuir a la IA enlazando cuentas personales (sociales, de salud o fintech) o completando tareas de datos. La testnet está abierta a nuevos participantes.
Enlace: app.getoro.xyz
Gata, @Gata_xyz, recaudó 4 millones de dólares
Como capa de datos descentralizada, Gata ofrece actualmente tres productos principales: Data Agent (agente de IA activado por navegador), All-in-one Chat (recompensas por evaluación de modelos, al estilo Yupp) y GPT-to-Earn (extensión de navegador para recopilar conversaciones de ChatGPT).
Enlace: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
¿Cómo debemos evaluar estos proyectos?
Actualmente, la barrera técnica de estos proyectos es baja, pero la retención de usuarios y el efecto de red crecen rápidamente. Es crucial invertir pronto en incentivos y experiencia de usuario: solo quien consiga una base de usuarios suficiente podrá liderar el mercado de datos.
Al ser proyectos intensivos en mano de obra, las plataformas de datos deben gestionar tanto el equipo como la calidad de los datos. Muchos proyectos Web3 comparten el problema de que una mayoría de usuarios solo busca incentivos a corto plazo—los populares "farmers"—, a menudo en detrimento de la calidad. Si persiste esta tendencia, los malos actores desplazarán a los colaboradores valiosos, perjudicando la integridad de los datos y ahuyentando a los compradores. Sahara, Sapien y otros ya están dando prioridad a la calidad de datos y trabajan por establecer relaciones sólidas y sostenibles con sus contribuidores.
Otro reto es la falta de transparencia. El «trilema imposible» de blockchain implica que muchos proyectos nacen siendo más centralizados y presentan aún características de Web2, pese a operar en entorno Web3—con poca visibilidad de datos en blockchain y compromisos poco claros respecto a la apertura. Esto mina la salud a largo plazo de DataFi. Es deseable que más equipos sigan fieles a su filosofía y aceleren el proceso de apertura y transparencia.
Por último, para que DataFi logre una adopción masiva hacen falta dos cosas: atraer suficientes usuarios minoristas para alimentar el motor de datos y crear una economía cerrada de IA; y ganarse la confianza de las grandes empresas, que seguirán siendo la principal fuente de ingresos a corto plazo. En este frente, Sahara AI, Vana y proyectos afines ya han logrado avances tangibles.
Conclusión
En definitiva, DataFi consiste en canalizar la inteligencia humana para desarrollar la inteligencia artificial a largo plazo—usando contratos inteligentes que aseguren la justa recompensa a las contribuciones y permitan a las personas beneficiarse del avance de la inteligencia de las máquinas.
Para quienes sienten incertidumbre en la era de la IA, o mantienen la confianza en la tecnología blockchain pese a la volatilidad cripto, participar en DataFi puede ser una decisión inteligente y oportuna.
Aviso legal:
- Este artículo ha sido reproducido de [BLOCKBEATS] y los derechos corresponden al autor original [anci_hu49074, colaborador principal de Biteye]. Para cuestiones de reproducción, contacte con el equipo Gate Learn para su gestión conforme a los procedimientos vigentes.
- Aviso legal: Las opiniones aquí expresadas pertenecen exclusivamente al autor y no constituyen asesoramiento de inversión.
- Otras versiones idiomáticas han sido traducidas por el equipo Gate Learn. Salvo mención expresa de Gate, no está permitido reproducir, distribuir ni plagiar dichas traducciones.
Artículos relacionados

¿Qué es Tronscan y cómo puedes usarlo en 2025?

¿Qué es SegWit?

Todo lo que necesitas saber sobre Blockchain

¿Qué hace que Blockchain sea inmutable?

¿Qué es Stablecoin?
