نماذج توقع أسعار العملات الرقمية القائمة على تعلم الآلة: من LSTM إلى المحول
يُعرف سوق العملات الرقمية بتقلباته الشديدة، مما يوفر فرصًا كبيرة للمستثمرين، ولكنه يشكل أيضًا مخاطر كبيرة. التنبؤ الدقيق بالأسعار أمر حاسم لاتخاذ قرارات استثمارية مستنيرة. ومع ذلك، غالبًا ما تواجه أساليب التحليل المالي التقليدية صعوبات في التعامل مع تعقيدات وتحولات السوق الرقمي بسرعة. في السنوات الأخيرة، قدم تقدم الذكاء الاصطناعي أدوات قوية لتوقعات السلاسل الزمنية المالية، خاصة في توقع أسعار العملات الرقمية.
يمكن لخوارزميات التعلم الآلي أن تتعلم من حجم كبير من البيانات التاريخية للأسعار والمعلومات الأخرى ذات الصلة، مما يساعدها على تحديد الأنماط الصعبة التي يصعب على البشر اكتشافها. بين مختلف نماذج التعلم الآلي، فإن الشبكات العصبية العائدة (RNNs) ومشتقاتها مثل طرازات الذاكرة القصيرة الطويلة (LSTM) والمحول، قد لاقت اهتماما واسعا بفضل قدرتها الاستثنائية على التعامل مع البيانات التسلسلية، مما يظهر زيادة الإمكانيات في توقع أسعار العملات الرقمية. يقدم هذا المقال تحليلاً عميقًا لنماذج التوقعات السعرية للعملات الرقمية استنادًا إلى التعلم الآلي، مركزًا على مقارنة تطبيقات LSTM والمحول. كما يستكشف كيف يمكن أن تعزز دمج مصادر البيانات المتنوعة أداء النموذج ويفحص تأثير الأحداث السوداء على استقرار النموذج.
تطبيق تعلم الآلة في توقعات أسعار العملات الرقمية
الفكرة الأساسية لتعلم الآلة هي تمكين الكمبيوترات من التعلم من مجموعات البيانات الكبيرة والقيام بالتنبؤات استنادًا إلى الأنماط المتعلمة. تحليل هذه الخوارزميات للتغييرات التاريخية في الأسعار وأحجام التداول وغيرها من البيانات ذات الصلة لاكتشاف الاتجاهات والأنماط الخفية. تتضمن النهج الشائعة تحليل الانحدار وشجرة القرار والشبكات العصبية، جميعها تم استخدامها على نطاق واسع في بناء نماذج توقعات أسعار العملات الرقمية.
اعتمدت معظم الدراسات على الأساليب الإحصائية التقليدية في المراحل الأولى من توقعات أسعار العملات الرقمية. على سبيل المثال، حوالي عام 2017، قبل انتشار التعلم العميق، استخدم العديد من الدراسات نماذج ARIMA لتوقع اتجاهات أسعار العملات الرقمية مثل البيتكوين. استخدمت دراسة ممثلة من قبل دونغ، لي، وغونغ (2017) نموذج ARIMA لتحليل تقلب البيتكوين، مما يدل على استقرار وموثوقية النماذج التقليدية في التقاط الاتجاهات الخطية.
مع التقدم التكنولوجي، بدأت طرق التعلم العميق تظهر نتائج مبكرة في توقعات سلاسل زمنية مالية بحلول عام 2020. وعلى وجه الخصوص، حظيت شبكات الذاكرة القصيرة الطويلة الأجل (LSTM) بشعبية بسبب قدرتها على التقاط التبعيات طويلة المدى في بيانات السلاسل الزمنية. دراسةبينما أثبت باتيل وآخرون (2019) مزايا نموذج الذاكرة القصيرة الطويلة في توقع أسعار البيتكوين، مما يشكل تقدماً كبيراً في ذلك الوقت.
بحلول عام 2023، بدأت نماذج Transformer - مع آليات الانتباه الذاتي الفريدة لديها القدرة على التقاط العلاقات عبر تسلسل البيانات بأكمله في وقت واحد - تُطبق بشكل متزايد على توقعات سلاسل الزمن المالية. على سبيل المثال، في 2023 لـ Zhao وآخرون.دراسةنجحت "الانتباه! المحول مع المشاعر على توقعات أسعار العملات الرقمية" في دمج نماذج المحول مع بيانات المشاعر على وسائل التواصل الاجتماعي، مما ساهم في تحسين دقة توقعات اتجاه أسعار العملات الرقمية بشكل كبير، وهو إنجاز كبير في هذا المجال.

المعالم الرئيسية في تكنولوجيا توقع العملات الرقمية (المصدر: بوابة تعلم الخالق جون)
من بين العديد من نماذج التعلم الآلي ، أظهرت نماذج التعلم العميق - وخاصة الشبكات العصبية المتكررة (RNNs) وإصداراتها المتقدمة ، LSTM و Transformer - مزايا كبيرة في التعامل مع بيانات السلاسل الزمنية. تم تصميم RNNs خصيصا لمعالجة البيانات المتسلسلة عن طريق تمرير المعلومات من الخطوات السابقة إلى الخطوات اللاحقة ، والتقاط التبعيات بشكل فعال عبر النقاط الزمنية. ومع ذلك ، فإن RNNs التقليدية تكافح مع مشكلة "التدرج المتلاشي" عند التعامل مع التسلسلات الطويلة ، مما يتسبب في فقدان المعلومات القديمة ولكن المهمة تدريجيا. لمعالجة هذا الأمر ، يقدم LSTM خلايا الذاكرة وآليات البوابات فوق RNNs ، مما يتيح الاحتفاظ بالمعلومات الأساسية على المدى الطويل ونمذجة التبعيات طويلة المدى بشكل أفضل. نظرا لأن البيانات المالية ، مثل أسعار العملات المشفرة التاريخية ، تظهر خصائص زمنية قوية ، فإن نماذج LSTM مناسبة بشكل خاص للتنبؤ بمثل هذه الاتجاهات.
من ناحية أخرى، تم تطوير نماذج ترانسفورمر أصلاً لمعالجة اللغة. آلية الانتباه الذاتي فيها تتيح للنموذج مراعاة العلاقات عبر تسلسل البيانات بأكمله بشكل متزامن، بدلاً من معالجتها خطوة بخطوة. تعطي هذه الهندسة المعمارية للترانسفورمرز إمكانية هائلة في توقع البيانات المالية ذات التبعيات الزمنية المعقدة.
مقارنة النماذج التنبؤية
النماذج التقليدية مثل ARIMA غالبًا ما تستخدم كقواعد بجانب نماذج التعلم العميق في توقع أسعار العملات الرقمية. تم تصميم ARIMA لالتقاط الاتجاهات الخطية والتغييرات النسبية المتسقة في البيانات، مما يؤدي إلى أداء جيد في العديد من مهام التنبؤ. ومع ذلك، نظرًا لطبيعة أسعار العملات الرقمية العالية التقلب والمعقدة، فإن افتراضات الخطية لـ ARIMA غالبًا ما تكون غير كافية.وقد أظهرت الدراساتأن نماذج التعلم العميق عمومًا توفر توقعات أكثر دقة في الأسواق غير الخطية والمتقلبة بشكل كبير.
بين النهج العميقة التعلم، وجدت الأبحاث التي تقارن بين نماذج LSTM والمحولات في توقع أسعار البيتكوين أن LSTM يؤدي بشكل أفضل عند التقاط التفاصيل الدقيقة لتغييرات الأسعار على المدى القصير. يعود هذا التفوق أساسا إلى آلية الذاكرة في LSTM، التي تمكنه من تصميم التبعيات على المدى القصير بشكل أكثر فعالية وثباتًا. بينما قد يتفوق LSTM في دقة التنبؤ على المدى القصير، فإن نماذج المحولات تظل تنافسية للغاية. عند تعزيزها ببيانات سياقية إضافية - مثل تحليل المشاعر من تويتر - يمكن أن تقدم المحولات فهمًا أوسع للسوق، مما يحسن بشكل كبير من الأداء التنبؤي.
وعلاوة على ذلك، قامت بعض الدراسات باستكشاف نماذج هجينة تجمع بين التعلم العميق والنهج الإحصائي التقليدي، مثل LSTM-ARIMA. تهدف هذه النماذج الهجينة إلى التقاط الأنماط الخطية وغير الخطية في البيانات، مما يعزز دقة التنبؤ وصلابة النموذج.
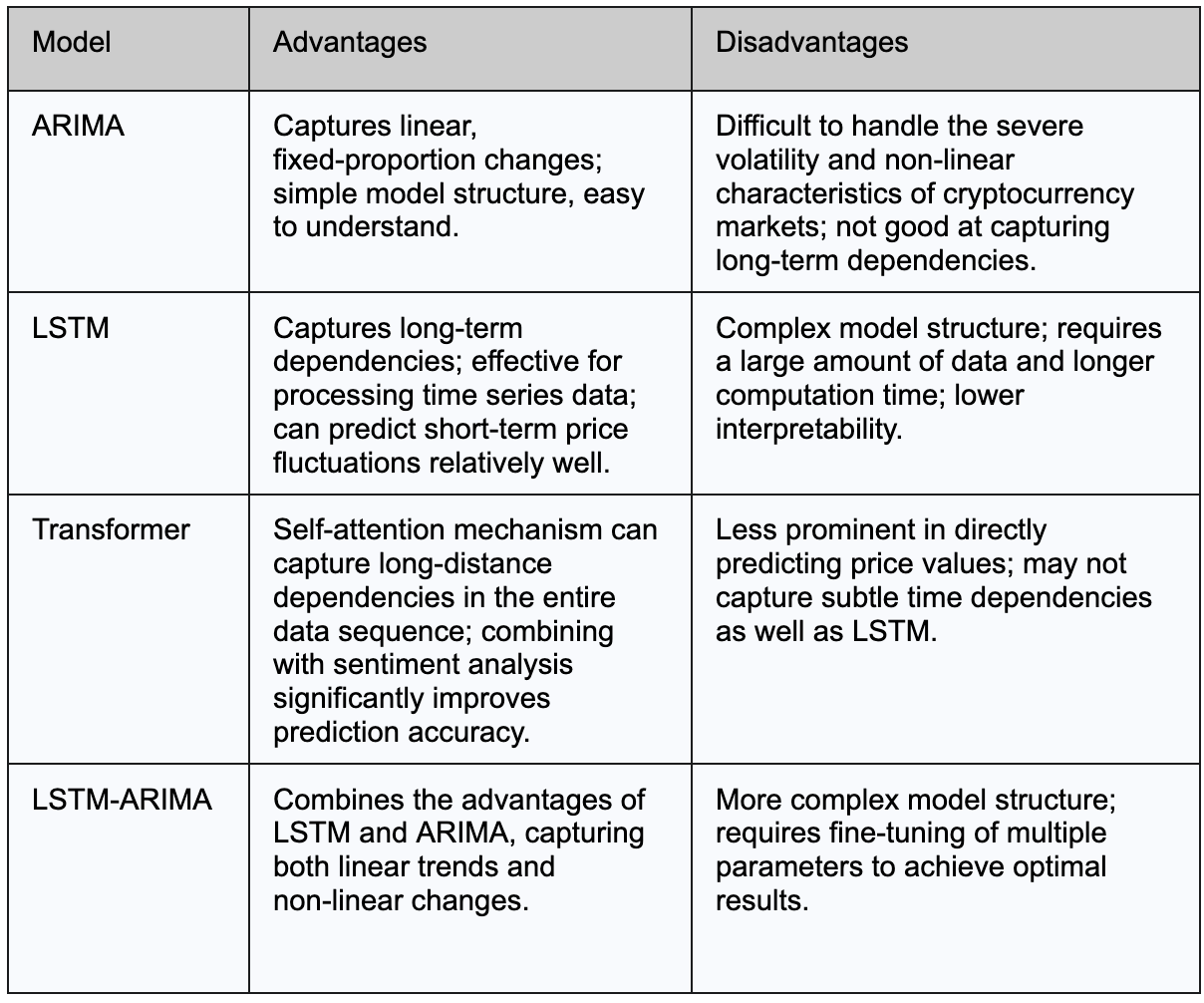
الجدول أدناه يلخص المزايا والعيوب الرئيسية لنماذج ARIMA و LSTM و Transformer في توقع سعر بيتكوين:
تحسين دقة التنبؤ باستخدام هندسة الميزات
عند التنبؤ بأسعار العملات المشفرة، لا نعتمد فقط على بيانات الأسعار التاريخية - بل نقوم أيضا بدمج معلومات قيمة إضافية لمساعدة النماذج على إجراء تنبؤات أكثر دقة. تسمى هذه العملية هندسة الميزات ، والتي تتضمن تنظيم وبناء "ميزات" البيانات التي تعزز أداء التنبؤ.
مصادر بيانات الميزات الشائعة
بيانات سلسلة الكتل
بيانات السلسلةيشير إلى جميع المعلومات التجارية والنشاطات المسجلة على سلسلة الكتل، بما في ذلك حجم التداول، وعدد عناوين النشاط النشطة، صعوبة التعدين، و معدل الهاش. تعكس هذه المقاييس مباشرة ديناميات العرض والطلب في السوق والنشاط الشبكي العام، مما يجعلها قيمة للغاية في توقعات الأسعار. على سبيل المثال، قد يشير زيادة كبيرة في حجم التداول إلى تحول في مشاعر السوق، بينما قد يشير زيادة في العناوين النشطة إلى اعتماد أوسع، مما قد يدفع الأسعار للأعلى بشكل محتمل.
يتم الوصول عادة إلى مثل هذه البيانات عبر واجهات برمجة تطبيقات مستكشف البلوكشين أو مزودي بيانات متخصصين مثل Glassnodeومقاييس العملةيمكنك استخدام مكتبة طلبات Python لاستدعاء واجهات برمجة التطبيقات أو تنزيل ملفات CSV مباشرة للتحليل.
مؤشرات المشاعر على وسائل التواصل الاجتماعي
المنصات مثل سانتيمنتتحليل محتوى النص من مصادر مثل تويتر وريديت لتقييم مشاعر المشاركين في السوق تجاه العملات الرقمية. يقومون كذلك بتطبيق تقنيات معالجة اللغة الطبيعية (NLP) مثل تحليل المشاعر لتحويل هذا النص إلى مؤشرات المشاعر. تعكس هذه المؤشرات آراء المستثمرين وتوقعاتهم، مما يقدم مدخلًا قيمًا لتوقع الأسعار. على سبيل المثال، قد تجذب المشاعر الإيجابية بشكل سائد على وسائل التواصل الاجتماعي المزيد من المستثمرين وتدفع الأسعار إلى الارتفاع، بينما قد تُشكل المشاعر السلبية ضغطًا على البيع. تقدم منصات مثل Santiment أيضًا واجهات برمجة تطبيقات (APIs) وأدوات لمساعدة المطورين في دمج بيانات المشاعر في نماذج التوقع.أظهرت الدراساتأن دمج تحليل المشاعر على وسائل التواصل الاجتماعي يمكن أن يعزز بشكل كبير أداء نماذج توقعات أسعار العملات الرقمية، خاصة بالنسبة للتنبؤات على المدى القصير.

سانتيمنت يمكن أن توفر بيانات المشاعر حول آراء المشاركين في السوق حول العملات الرقمية (المصدر: سانتيمنت)
العوامل الاقتصادية الكبرى
مؤشرات الاقتصاد الكلي مثل أسعار الفائدة وأسعار التضخم ونمو الناتج المحلي الإجمالي ومعدلات البطالة تؤثر أيضًا على أسعار العملات الرقمية. تؤثر هذه العوامل على تفضيلات المستثمرين للمخاطر وتدفقات رؤوس الأموال. على سبيل المثال، قد يقوم المستثمرون بتحويل الأموال من الأصول عالية المخاطر مثل العملات الرقمية إلى بدائل أكثر أمانًا عندما ترتفع أسعار الفائدة، مما يؤدي إلى انخفاض الأسعار. من ناحية أخرى، عندما يرتفع التضخم، قد يبحث المستثمرون عن الأصول الحافظة على القيمة- يُنظر في بعض الأحيان إلى بيتكوين كحماية ضد التضخم.
يمكن الحصول على بيانات عن أسعار الفائدة والتضخم ونمو الناتج المحلي الإجمالي ومعدل البطالة عادةً من الحكومات الوطنية أو المنظمات الدولية مثل البنك الدولي أو صندوق النقد الدولي. تكون هذه المجموعات من البيانات عادةً متاحة في تنسيق CSV أو JSON ويمكن الوصول إليها من خلال مكتبات Python مثل pandas_datareader.
الجدول التالي يلخص البيانات المستخدمة على نطاق واسع على السلسلة البيانية، ومؤشرات المشاعر على وسائل التواصل الاجتماعي، والعوامل الاقتصادية الكبرى، بالإضافة إلى كيفية تأثيرها على أسعار العملات الرقمية:

كيفية دمج بيانات الميزات
عموماً، يمكن تقسيم هذه العملية إلى عدة خطوات:
1. تنظيف البيانات والموحدة
البيانات من مصادر مختلفة قد تكون لها تنسيقات مختلفة، قد تكون بعضها مفقودة أو غير متناسقة. في مثل هذه الحالات، يكون تنظيف البيانات ضروريًا. على سبيل المثال، تحويل جميع البيانات إلى نفس تنسيق التاريخ، وملء البيانات المفقودة، وتوحيد البيانات بحيث يمكن مقارنتها بسهولة أكبر.
2. تكامل البيانات
بعد التنظيف، يتم دمج البيانات من مصادر مختلفة استناداً إلى التواريخ، مما يخلق مجموعة بيانات كاملة تظهر الظروف السوقية لكل يوم.
3. بناء إدخال النموذج
وأخيرًا، يتم تحويل هذه البيانات المتكاملة إلى تنسيق يمكن للنموذج فهمه. على سبيل المثال، إذا أردنا من النموذج توقع سعر اليوم بناءً على البيانات من الـ 60 يومًا الماضية، فسننظم البيانات من تلك الـ 60 يومًا في قائمة (أو مصفوفة) لتكون كإدخال للنموذج. يتعلم النموذج العلاقات داخل هذه البيانات لتوقع اتجاهات الأسعار المستقبلية.
يمكن للنموذج الاستفادة من معلومات أكثر شمولية لتحسين دقة التنبؤ من خلال عملية هندسة الميزات هذه.
أمثلة على مشاريع مفتوحة المصدر
هناك العديد من مشاريع توقعات أسعار العملات الرقمية مفتوحة المصدر الشهيرة على موقع GitHub. تستخدم هذه المشاريع مختلف نماذج التعلم الآلي والتعلم العميق لتوقع اتجاهات الأسعار لمختلف العملات الرقمية.
يستخدم معظم المشاريع إطارات التعلم العميق الشهيرة مثل TensorFlowأوكيراسلبناء وتدريب النماذج، وتعلم الأنماط من البيانات التاريخية للأسعار، وتوقع حركات الأسعار المستقبلية. يتضمن العملية بشكل عام معالجة البيانات (مثل تنظيم وتوحيد البيانات التاريخية للأسعار)، بناء النموذج (تحديد طبقات LSTM وغيرها من الطبقات اللازمة)، تدريب النموذج (ضبط معلمات النموذج من خلال مجموعة بيانات كبيرة لتقليل أخطاء التنبؤ)، والتقييم النهائي وتصوير نتائج التنبؤ.
واحد من المشاريع التي تستخدم تقنيات التعلم العميق لتوقع أسعار العملات الرقمية هو Dat-TG/العملات الرقمية-توقعات الأسعار.
الهدف الرئيسي لهذا المشروع هو استخدام نموذج LSTM لتوقع أسعار إغلاق البيتكوين (BTC-USD)، الإيثيريوم (ETH-USD)، وكاردانو (ADA-USD) لمساعدة المستثمرين على فهم اتجاهات السوق بشكل أفضل. يمكن للمستخدمين استنساخ مستودع الـ GitHub وتشغيل التطبيق محليًا باتباع التعليمات المقدمة.

نتائج توقعات BTC للمشروع (المصدر: لوحة أسعار العملات الرقمية
هيكل الكود لهذا المشروع واضح، مع سكريبتات منفصلة ودفاتر Jupyter للحصول على البيانات، تدريب النموذج، وتشغيل تطبيق الويب. استنادًا إلى هيكل دليل المشروع والبنية الداخلية الشفرة، عملية بناء نموذج التنبؤ كما يلي:
- يتم تحميل البيانات من ياهو فاينانس، ثم تُنظف وتُنظم باستخدام باندا، بما في ذلك المهام مثل توحيد تنسيق التاريخ وملء القيم المفقودة.
- تُولِد البيانات المعالجة "نافذة منزلقة" — باستخدام البيانات التي تعود للوراء 60 يومًا لتوقع السعر في اليوم 61.
- ثم يتم تغذية البيانات إلى نموذج يتم بناؤه باستخدام LSTM (الذاكرة القصيرة والطويلة الأجل). يتذكر LSTM بشكل فعال التغييرات السعرية القصيرة والطويلة الأجل، مما يجعله مناسبًا تمامًا لتوقع اتجاهات الأسعار.
- تظهر نتائج التنبؤ والأسعار الفعلية باستخدام مخططات متنوعة من خلال Plotly Dash، مع قائمة منسدلة تتيح للمستخدمين تحديد العملات الرقمية المختلفة أو المؤشرات الفنية، مع تحديث المخططات في الوقت الحقيقي.

هيكل الدليل للمشروع (المصدر: العملات الرقمية-التنبؤ بأسعار العملات)
تحليل مخاطر نموذج توقع سعر العملات الرقمية
تأثير الأحداث السوداء على استقرار النموذج
حدث البجعة السوداء نادر للغاية وغير قابل للتنبؤ بأثر هائل. هذه الأحداث عادة ما تكون خارج توقعات النماذج التنبؤية التقليدية ويمكن أن تتسبب في اضطراب كبير في السوق. مثال نموذجي هوتحطم لونافي مايو 2022.
لونا، كمشروع لعملة مستقرة خوارزمية، اعتمدت على آلية معقدة مع عملة شقيقتها لونا من أجل الاستقرار. في بداية مايو 2022، بدأت العملة المستقرة UST التابعة للونا في الانفصال عن الدولار الأمريكي، مما أدى إلى بيع بانيكي من قبل المستثمرين. نتيجة لعيوب الآلية الخوارزمية، تسبب انهيار UST في زيادة إمدادات لونا بشكل كبير. خلال بضعة أيام، هوى سعر لونا من ما يقرب من 80 دولارًا إلى الصفر تقريبًا، مما تجنب مئات المليارات من الدولارات في قيمة السوق. هذا تسبب في خسائر كبيرة للمستثمرين المعنيين وأثار مخاوف واسعة حول المخاطر النظامية في سوق العملات الرقمية.
وبالتالي، عندما يحدث حدث البجعة السوداء، فإن النماذج التعليمية التقليدية للتعلم الآلي التي تم تدريبها على البيانات التاريخية من المحتمل أن لم تواجه مثل هذه الحالات القصوى أبدًا، مما يؤدي إلى فشل النماذج في اتخاذ تنبؤات دقيقة أو حتى إنتاج نتائج مضللة.
المخاطر الجوهرية للنموذج
بالإضافة إلى أحداث البجعة السوداء، يجب علينا أيضًا أن نكون على علم ببعض المخاطر الجوهرية في النموذج نفسه، والتي قد تتراكم تدريجيًا وتؤثر على دقة التنبؤ في الاستخدام اليومي.
(1) انحراف البيانات والقيم الشاذة
في سلاسل زمنية مالية، تظهر البيانات في كثير من الأحيان انحرافًا أو تحتوي على قيم غير معتادة. إذا لم يتم إجراء المعالجة الأولية للبيانات بشكل صحيح، فقد يتم تعطيل عملية تدريب النموذج بواسطة الضوضاء، مما يؤثر على دقة التنبؤ.
(2) النماذج المبسطة للغاية والتحقق غير الكافي
قد تعتمد بعض الدراسات بشكل مفرط على هيكل رياضي واحد عند بناء النماذج، مثل استخدام نموذج ARIMA فقط لالتقاط الاتجاهات الخطية مع تجاهل العوامل غير الخطية في السوق. يمكن أن يؤدي هذا إلى تبسيط النموذج. بالإضافة إلى ذلك، يمكن أن تؤدي عدم الكفاية في التحقق من صحة النموذج إلى أداء اختبار الرجوع المفرط التفاؤلي، ولكن النتائج الضعيفة في التنبؤ في التطبيقات الفعلية (على سبيل المثال، التجاوز الزائديؤدي إلى أداء ممتاز على البيانات التاريخية ولكن هناك انحراف كبير في استخدام العالم الحقيقي)
(3) مخاطر تأخر بيانات واجهة برمجة التطبيقات
في التداول الحي، إذا اعتمد النموذج على واجهات برمجة التطبيقات للحصول على البيانات في الوقت الحقيقي، فإن أي تأخير في الواجهة البرمجية أو فشل في تحديث البيانات في الوقت المناسب يمكن أن يؤثر مباشرة على عمل النموذج ونتائج التنبؤ، مما يؤدي إلى فشل التداول الحي.
تدابير لتعزيز استقرار نموذج التنبؤ
في مواجهة المخاطر المذكورة أعلاه، يجب اتخاذ التدابير المناسبة لتحسين استقرار النموذج. الاستراتيجيات التالية مهمة بشكل خاص:
(1) مصادر بيانات متنوعة ومعالجة البيانات
تجميع مصادر البيانات المتعددة (مثل الأسعار التاريخية، حجم التداول، بيانات المشاعر الاجتماعية، إلخ) يمكن أن يعوض عن نقاط الضعف في نموذج واحد، في حين يجب إجراء تنظيف البيانات بدقة، وتحويلها، وتقسيمها. هذا النهج يعزز قدرة النموذج على التعميم ويقلل من المخاطر الناجمة عن انحرافات البيانات والقيم الشاذة.
(2) اختيار مقاييس تقييم النموذج المناسبة
خلال عملية بناء النموذج، من الضروري اختيار مقاييس التقييم المناسبة استنادًا إلى خصائص البيانات (مثل MAPE، RMSE، AIC، BIC، إلخ) لتقييم أداء النموذج وتجنب الاحتكاك الزائد بشكل شامل. العمليات المنتظمة للتقييم المتقاطع والتنبؤ المتداولين أيضًا خطوات حرجة لتحسين قوة النموذج.
(3) التحقق من النموذج والتكرار
بمجرد إنشاء النموذج، يجب أن يخضع للتحقق الدقيق باستخدام تحليل البقايا وآليات كشف الشذوذ. يجب تعديل استراتيجية التنبؤ بشكل مستمر استنادًا إلى تغيرات السوق. على سبيل المثال، إدخال التعلم الحساس للسياق لضبط معلمات النموذج وفقًا للظروف السوقية الحالية هو أحد النهج. بالإضافة إلى ذلك، دمج النماذج التقليدية مع النماذج العميقة لتشكيل نموذج هجين هو طريقة فعالة لتحسين دقة التنبؤ واستقراره.
الانتباه إلى مخاطر الامتثال
أخيرًا، بالإضافة إلى المخاطر التقنية، يجب أن تُعتَبَر مخاطر الخصوصية والامتثال للبيانات عند استخدام مصادر البيانات غير التقليدية مثل بيانات المشاعر. على سبيل المثال، هيئة الأوراق المالية والبورصات الأمريكية (لجنة الأوراق المالية والبورصات)لديها متطلبات مراجعة صارمة بشأن جمع واستخدام بيانات المشاعر لمنع الاختلافات القانونية الناشئة عن قضايا الخصوصية.
هذا يعني أنه أثناء عملية جمع البيانات ، يجب أن تكون معلومات التعريف الشخصية (مثل أسماء المستخدمين والتفاصيل الشخصية وما إلى ذلك) مجهولة المصدر. يهدف هذا إلى منع تعرض الخصوصية الشخصية مع تجنب الاستخدام غير السليم للبيانات. بالإضافة إلى ذلك ، من الضروري التأكد من أن مصادر البيانات التي تم جمعها مشروعة ولم يتم الحصول عليها من خلال وسائل غير لائقة (مثل تجريف الويب غير المصرح به). من الضروري أيضا الكشف علنا عن طرق جمع البيانات واستخدامها ، مما يسمح للمستثمرين والهيئات التنظيمية بفهم كيفية معالجة البيانات وتطبيقها. تساعد هذه الشفافية على منع استخدام البيانات للتلاعب بمعنويات السوق.
الاستنتاج والتوقعات المستقبلية
في الختام، تظهر نماذج توقعات أسعار العملات الرقمية القائمة على تعلم الآلة إمكانات كبيرة في مواجهة تقلبات السوق وتعقيداتها. ستكون توجيهات مهمة لتطوير مستقبل توقعات أسعار العملات الرقمية استراتيجيات إدارة المخاطر المتكاملة واستكشاف بشكل مستمر لتصميمات النماذج الجديدة وأساليب دمج البيانات. مع تقدم تكنولوجيا تعلم الآلة، نعتقد أن ستظهر نماذج توقعات أسعار العملات الرقمية الأكثر دقة واستقرارًا، مما يوفر للمستثمرين دعمًا أقوى في اتخاذ القرارات.
مقالات ذات صلة

كيف تعمل بحوثك الخاصة (Dyor)؟

أفضل 10 منصات تداول العملات الميمية

ما هو التحليل الأساسي؟

أفضل 7 بوتات مدعومة بالذكاء الاصطناعي على تليجرام في عام 2025

كل ما تحتاج لمعرفته حول التداول بالاستراتيجية الكمية
